Qu’est-ce que l’exploration de données ?
L’exploration de données est le processus qui consiste à trier de grands ensembles de données pour identifier des modèles et des relations qui peuvent aider à résoudre des problèmes commerciaux par l’analyse des données. Les techniques et outils d’exploration de données permettent aux entreprises de prédire les tendances futures et de prendre des décisions commerciales plus éclairées.
L’exploration de données est un élément clé de l’analyse des données en général et l’une des disciplines fondamentales de la science des données, qui utilise des techniques d’analyse avancées pour trouver des informations utiles dans les ensembles de données.

Pourquoi l’exploration de données est-elle importante ?
L’exploration de données est une composante essentielle des initiatives analytiques réussies dans les organisations. Les informations qu’elle génère peuvent être utilisées dans des applications de veille stratégique (BI) et d’analyse avancée qui impliquent l’analyse de données historiques, ainsi que dans des applications d’analyse en temps réel qui examinent les données en continu au moment où elles sont créées ou collectées.
L’exploration efficace des données contribue à divers aspects de la planification des stratégies commerciales et de la gestion des opérations. Cela inclut les fonctions en contact avec la clientèle, telles que le marketing, la publicité, les ventes et le support client, ainsi que la fabrication, la gestion de la chaîne d’approvisionnement, les finances et les RH. L’exploration de données facilite la détection des fraudes, la gestion des risques, la planification de la cybersécurité et de nombreux autres cas d’utilisation critiques pour les entreprises. Elle joue également un rôle important dans les soins de santé, les administrations, la recherche scientifique, les mathématiques, les sports, etc.

Processus d’exploration des données : Comment cela fonctionne-t-il ?
L’exploration de données est généralement effectuée par des spécialistes des données et d’autres professionnels qualifiés de la BI et de l’analyse. Mais il peut également être effectué par des analystes commerciaux, des cadres et des travailleurs qui ont une bonne connaissance des données et qui jouent le rôle de scientifiques des données dans une organisation.
Ses principaux éléments sont l’apprentissage automatique et l’analyse statistique, ainsi que les tâches de gestion des données effectuées pour préparer les données à l’analyse. L’utilisation d’algorithmes d’apprentissage automatique et d’outils d’intelligence artificielle (IA) a permis d’automatiser une grande partie du processus et de faciliter l’extraction d’ensembles de données massifs, tels que les bases de données clients, les enregistrements de transactions et les fichiers journaux des serveurs web, des applications mobiles et des capteurs.
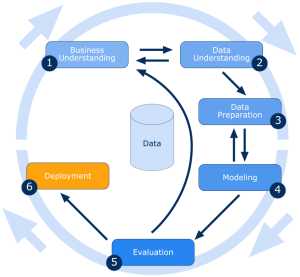
Le processus d’exploration des données peut être décomposé en quatre étapes principales
1-La collecte des données.
Les données pertinentes pour une application analytique sont identifiées et assemblées. Les données peuvent être situées dans différents systèmes sources, un entrepôt de données (data warehouse) ou un lac de données (data lake), ces différents lieux de stockage de plus en plus courant dans les environnements de big data contiennent un mélange de données structurées et non structurées. Des sources de données externes peuvent également être utilisées. Quelle que soit la provenance des données, un data scientist les déplace souvent vers un lac de données pour les autres étapes du processus.

2-Préparation des données .
Cette étape comprend un ensemble d’étapes pour que les données soient prêtes à être exploitées. Elle commence par l’exploration, le profilage et le prétraitement des données, suivis d’un travail de nettoyage des données pour corriger les erreurs et autres problèmes de qualité des données. La transformation des données est également effectuée pour rendre les ensembles de données cohérents, à moins qu’un data scientist ne cherche à analyser des données brutes non filtrées pour une application particulière.

3- Extraction des données.
Une fois les données préparées, le spécialiste des données choisit la technique d’exploration des données appropriée et met en œuvre un ou plusieurs algorithmes pour effectuer l’exploration. Dans les applications d’apprentissage automatique, les algorithmes doivent généralement être entraînés sur des ensembles de données échantillons pour rechercher les informations recherchées avant d’être exécutés sur l’ensemble des données.
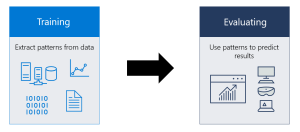
4- Analyse et interprétation des données.
Les résultats de l’exploration des données sont utilisés pour créer des modèles analytiques qui peuvent contribuer à la prise de décision et à d’autres actions commerciales. Le data scientist ou un autre membre de l’équipe de data science doit également communiquer les résultats aux dirigeants et aux utilisateurs de l’entreprise, souvent par la visualisation des données et l’utilisation de techniques de narration des données.

Récapitulatif du processus de Data Mining en image